每日經(jīng)濟新聞 2025-02-25 21:17:40
2月24日,DeepSeek發(fā)布首個開源項目FlashMLA,該項目適用于Hopper GPU的高效MLA解碼內(nèi)核。有觀點認為,目前限制DeepSeek推理的主要瓶頸就是顯存,F(xiàn)lashMLA則是“以算代存”。PPIO派歐云王聞宇指出,DeepSeek模型與其他主流模型相比參數(shù)量更大,決定了其需要更大容量顯存以加載模型權(quán)重,顯存容量是門檻,不是瓶頸。
每經(jīng)記者 朱成祥 每經(jīng)編輯 魏官紅
2月24日上午,DeepSeek(深度求索)發(fā)布首個開源項目FlashMLA。根據(jù)DeepSeek在GitHub社區(qū)披露的信息,F(xiàn)lashMLA是適用于Hopper GPU(一種英偉達圖形處理器架構(gòu))的高效MLA(多頭潛注意力)解碼內(nèi)核,針對可變長度序列服務進行了優(yōu)化。在H800(一款英偉達芯片)上可以實現(xiàn)每秒處理3000GB(千兆字節(jié))數(shù)據(jù),每秒執(zhí)行580萬億次浮點運算。
有業(yè)內(nèi)觀點認為,目前限制DeepSeek推理的主要瓶頸就是顯存,F(xiàn)lashMLA則是“以算代存”,可解決推理過程中顯存容量不足的問題。
對此,PPIO派歐云聯(lián)合創(chuàng)始人兼CTO王聞宇告訴《每日經(jīng)濟新聞》記者:“(該觀點)不完全正確,MLA的本質(zhì)是在基礎算法上的創(chuàng)新,通過將KV的權(quán)重矩陣轉(zhuǎn)換到潛空間,實現(xiàn)矩陣的大幅壓縮并且不造成精度損失。壓縮算法會引入微弱的計算量的增加,但是由此帶來的數(shù)據(jù)存儲開銷大幅下降,訓練及推理速度大幅提升,需要計算的數(shù)據(jù)總量減少了,總計算量反而減少了,相應的訓練和推理速度就會大幅提高。”
當下,外界普遍使用顯存來測算部署DeepSeek各類模型所需要的推理算力。比如根據(jù)民生證券研報,像DeepSeek-R1一個專注于實時推理的優(yōu)化版本,擁有15B參數(shù),推理時激活全部15B參數(shù),顯存需求約為30GB(FP16精度),單張NVIDIA A100(英偉達顯卡)或單張RTX 4090(英偉達消費級顯卡)等顯卡可滿足需求。
像DeepSeek 67B是一個擁有67B參數(shù)的大型模型,推理時激活全部67B參數(shù),顯存需求約為140GB(FP16精度)。推薦使用4張A100-80G GPU進行多卡并行推理。
照此計算,DeepSeek R1“滿血版”擁有671B參數(shù),在FP16精度下,需要1.4TB(太字節(jié))顯存;在FP8精度下,也需要約700GB顯存。如果按照一個服務器8張卡計算,單卡80GB的8卡服務器滿足不了“滿血版”的推理工作,可能需要多個服務器互連。
關(guān)于顯存是否為限制DeepSeek推理的主要瓶頸,王聞宇認為:“DeepSeek模型與其他主流模型相比,參數(shù)量更大,決定了其需要更大容量顯存以加載模型權(quán)重,顯存容量是門檻,不是瓶頸。”
那么,參數(shù)量小得多的蒸餾模型是否滿足應用需求?王聞宇表示:“蒸餾版本與滿血版本相比,參數(shù)量少很多,比如Qwen-7B,只有滿血版671B的百分之一,參數(shù)量少,導致在模型性能上遠弱于滿血版,如何選擇模型取決于實際的應用場景,要求高的場景可能無法用蒸餾版本來滿足。”
一位不愿具名的算力芯片廠商高管對《每日經(jīng)濟新聞》記者表示:“AI行業(yè)從業(yè)者,不管是哪個環(huán)節(jié)的,包括模型公司、AI芯片公司等,都是圍繞一個三角形來做的,三角形的三個角分別是提高價值,提高或者保持用戶體驗,維持或者降低使用成本??提高價值就是要能解決更多問題,能解決更難的問題;模型規(guī)模起來后,一般來說會降低用戶體驗、提高成本??所以大家都在這個三角形中螺旋式地往上爬。”
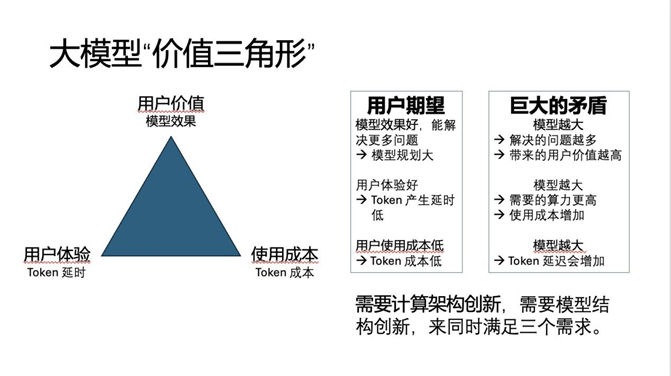
圖片來源:受訪對象提供
而FlashMLA,正是在大模型規(guī)模變大、能力變強后,在不降低用戶體驗的基礎上降低成本。
根據(jù)民生證券研報,傳統(tǒng)計算方式存在KV(鍵值)矩陣重復計算的問題,這不僅浪費了大量的計算資源,還會導致顯存消耗過大,影響模型的運行效率。而MLA技術(shù)解決了這個難題,它通過獨特的算法設計,減少了對KV矩陣的重復計算,大大降低了顯存的消耗。
需要注意的是,目前FlashMLA適配的是英偉達Hopper架構(gòu)的GPU。若FlashMLA在CUDA生態(tài)大幅減少對顯存的占用,那么未來應用到國內(nèi)算力芯片領(lǐng)域,是否有助于“推理平價”,降低推理成本,推動國產(chǎn)算力芯片在推理領(lǐng)域的使用?
沐曦工作人員反饋:“這一周大家都忙著DeepSeek開源周的適配。”另據(jù)沐曦官方微信號:“沐曦技術(shù)團隊在FlashMLA開源后迅速響應,僅用2小時即完成與沐曦GPU的適配工作,并于當日將代碼提交至開源社區(qū)。”
此外,沐曦方面也表示:“FlashMLA通過MLA解碼優(yōu)化與分頁KV緩存技術(shù)等顯著提升硬件利用率,可加速大語言模型解碼過程,有效提升響應速度與吞吐量,尤其適用于聊天機器人等實時生成場景。沐曦在適配中應用矩陣吸收算法將低秩投影融入Flash Attention 2核函數(shù),在保證計算效率的同時顯著降低顯存占用。”
PPIO派歐云王聞宇也表示:“FlashMLA對國內(nèi)算力芯片具有很大的借鑒價值,通過技術(shù)創(chuàng)新,將FlashMLA移植到國內(nèi)算力芯片上,也可以實現(xiàn)類似CUDA中的減少顯存占用和加速效果。”
事實上,除了通過算法領(lǐng)域的進步來減少顯存占用,也可以從芯片設計角度出發(fā),通過定制化的芯片來增加顯存。
上述算力芯片公司高管稱:“核心問題是HBM(高帶寬存儲)每GB是DDR(雙倍速率同步動態(tài)隨機存儲器)的5x(5倍)價錢,用HBM來存所有權(quán)重不劃算。”
其給出的解決辦法是多級存儲。他表示:“需要模型來進一步改造,我認為比較理想的軟硬件,在未來應該是兩級或者多級存儲的,比如HBM和DDR都上,HBM更快,DDR更大,所以整個模型都存更大的DDR里面,就像DeepSeek論文里面寫的,他們每10分鐘刷新一批redundant expert(冗余專家),這批可以放在HBM里面,用戶用的時候,大概率從這個redundant expert里面取expert,這樣就可以既便宜又快了。”
關(guān)于MoE結(jié)構(gòu)對算力硬件需求的變化,中金研報認為,可能帶來對處理器架構(gòu)進一步的定制化需求,如更大的計算單元、和更高效的通信kernel(內(nèi)核)相匹配的設計單元、近存計算單元等,利好DSA(領(lǐng)域?qū)S眉軜?gòu))架構(gòu)發(fā)展。
封面圖片來源:視覺中國-VCG41N1350722136
如需轉(zhuǎn)載請與《每日經(jīng)濟新聞》報社聯(lián)系。
未經(jīng)《每日經(jīng)濟新聞》報社授權(quán),嚴禁轉(zhuǎn)載或鏡像,違者必究。
讀者熱線:4008890008
特別提醒:如果我們使用了您的圖片,請作者與本站聯(lián)系索取稿酬。如您不希望作品出現(xiàn)在本站,可聯(lián)系我們要求撤下您的作品。
歡迎關(guān)注每日經(jīng)濟新聞APP

Copyright ? 2025 每日經(jīng)濟新聞報社版權(quán)所有,未經(jīng)許可不得轉(zhuǎn)載使用,違者必究。
廣告熱線? 北京: 010-57613265,?上海: 021-61283008,?廣州: 020-84201861,?深圳: 0755-83520159,?成都: 028-86512112












